
最近国产大模型异常的活跃
5月9日,阿里云正式发布通义千问2.5,表示模型性能全面赶超GPT-4 Turbo,成为地表最强中文大模型。
5月15日,2024春季火山引擎FORCE原动力大会在北京正式举办。会上正式发布了字节跳动豆包大模型家族、火山方舟2.0、AI应用及AI云基础设施等最新产品。
而相较于大模型的发布,这次大模型之间的价格战更是令人瞩目
其中,字节率先在发布会上表示豆包通用大模型pro-32k输入价格定价0.0008/千tokens
如果你对这个数据没有什么概念,举例来说:
1块钱可以买125万 tokens,而1个token大致等于1.5个汉字(参考OpenAI的Token计算:https://platform.openai.com/tokenizer),那么大致相当于 1.4 本《西游记》的文字量
所以你只需要1块钱,就可以输入将近125万汉字
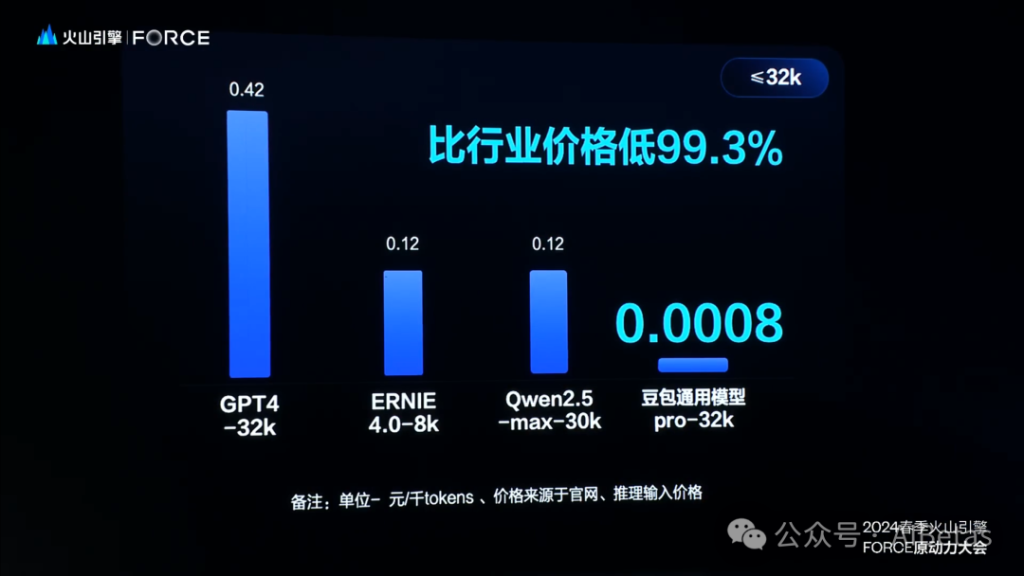
有趣的是,豆包大模型将百度文心大模型和阿里通义大模型的作为比较对象
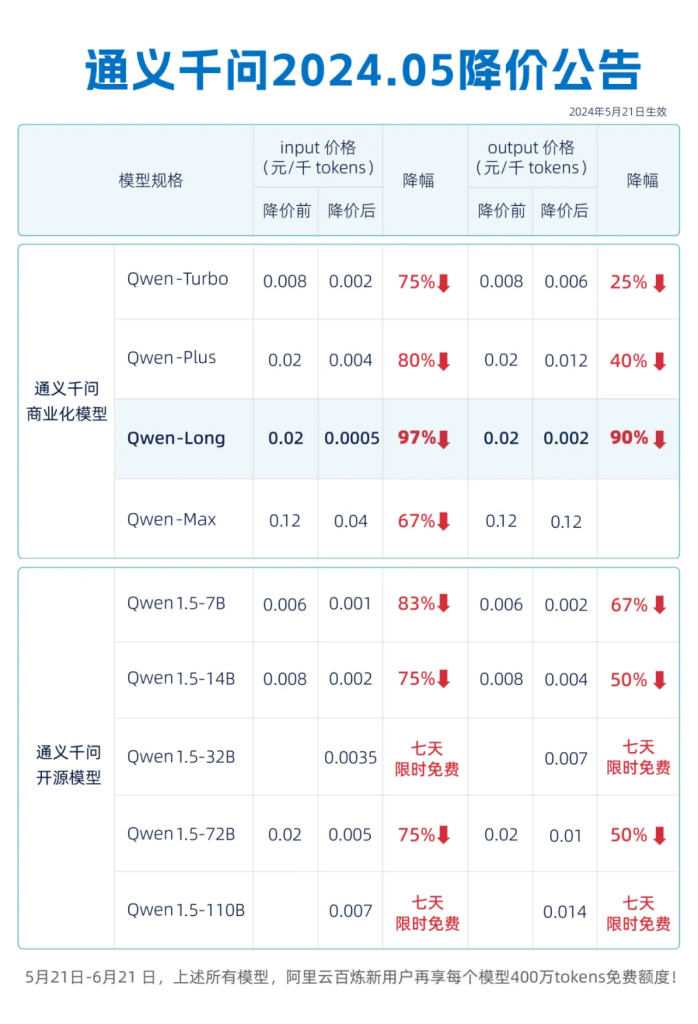
然后,这两家大模型火速就对自家大模型进行了价格调整
5月21日,通义千问率先表示GPT-4 级主力模型 Qwen-Long 宣布降价,API 输入价格从0.02 元 / 千 tokens 降至 0.0005 元 / 千 tokens,降幅 97%
这个价格比豆包大模型低了0.0003元/千 tokens,这比豆包大模型又降低了37.5%
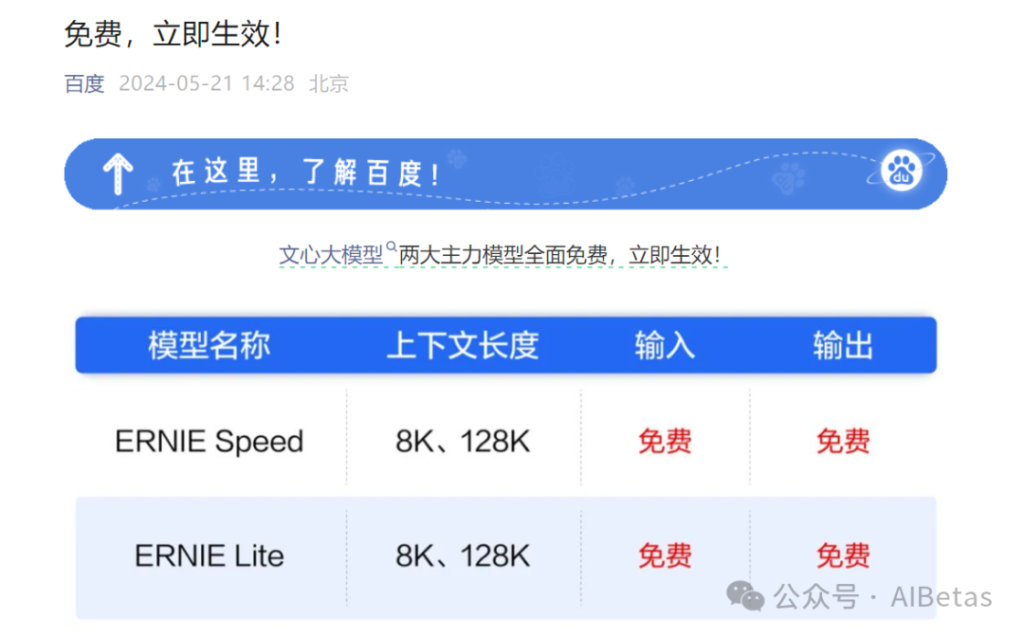
在阿里宣布降价4个小时后,百度更绝,直接宣布文心大模型两大主力模型ERNIE Speed和ERNIE Lite全面免费,立即生效!
我们对以上的价格进行一个汇总比较
![图片[4] - 国产AI大模型价格诸神之战,百度阿里字节已经杀疯了! - AIBetas](https://www.aibetas.com.cn/wp-content/uploads/2024/05/image-67.png)
大家普遍比较主要集中在输入价格上,而在输出价格方面,Daobao-pro-k和Qwen-Long的输出价格一致,均为0.002
模型输入调用量往往大于输出调用量,根据统计,真实的模型输入调用量一般是输出的8倍左右。
豆包大模型原名“云雀”,其中Doubao-pro是字节跳动自研LLM模型专业版,支持128K长文本。
Qwen-Long是通义千问模型家族中,提供具备强大长文本处理能力的模型,支持最长1000万tokens的超长上下文对话
ERNIE Speed、ERNIE Lite则是百度在今年3月份推出的轻量级大模型,均支持8K和128k上下文长度。
| 结语
这次的打折直接打到“骨折”,大厂之间的价格战就是这么朴实无华
将大模型的输入输出价格降下去,对企业和个人开发者来说是一个利好的消息,这也降低了大模型的使用门槛
在价格降下去的基础上,如何提升大模型的能力更是重中之重
一旁的GPT-4笑而不语
已经看到这里了,如果这篇文章对你有帮助,求个点赞,分享,转发,谢谢你的阅读!
